Automatic Tag Hierarchy System
Crowdsourced content databases have emerged as a significant repository of human knowledge. The information content of documents in these databases has been the focus of much study; however, there is another layer of information contained within these datasets. Many crowdsourced articles are tagged with important keywords which summarize their content. These keywords are primarily used to navigate the datasets, but what if they could be explored to understand the semantic relationships between the tags themselves?
The Automatic Tag Hierarchy System, developed jointly by Adam Mihalcin, Prashant Sridhar, and myself, uses machine learning techniques to acquire these relationships. The system scans a folksonomy of tags and documents, constructing a relatedness graph measuring the number of posts tagged by both tags compared to the number of posts tagged by the smaller tag of the pair. The intuition behind this weighting is that a tag which is often seen in the presence of another, bigger tag is likely subordinate in meaning to that larger tag.
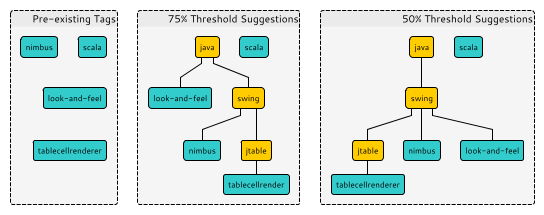
The system uses this relatedness graph to build a set of trees expressing related tag concepts. These trees can be used to suggest additional tags for new or existing content, or potentially to enhance the quality of document discovery across the database.
The Automatic Tag Hierarchy System was tested on the question corpus of Stack Overflow, the largest of the Stack Exchange family of question-and-answer communities. This dataset comprised 4.71 million posts, 32,400 tags, and a total of 13.7 million post-tag labeling relationships. A validation on this dataset was able to reconstruct 5.3% of tags for a given post when half of the tags were randomly removed. However, this is not a good measure of the System’s usefulness, as Stack Overflow limits to a maximum of 5 tags for each post. An ideal testing method would be to generate tag suggestions based upon the existing tags and then verify the correctness of those suggestions through human review. This methodology was beyond the time and budget available during this project, but is a candidate for future work on the subject.